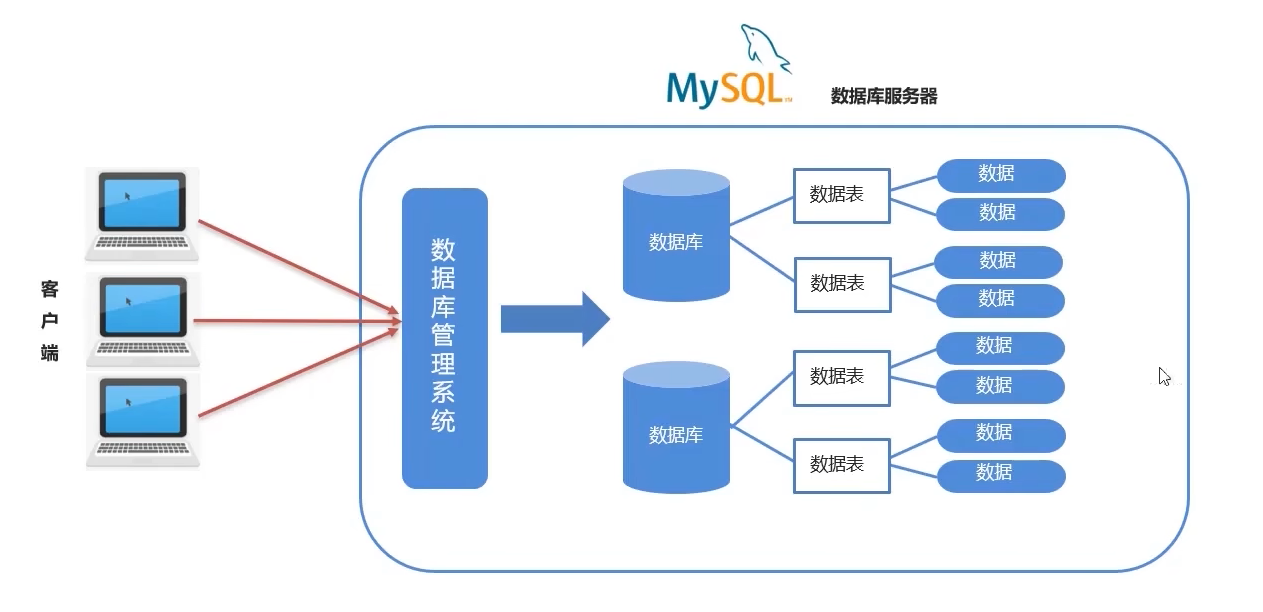
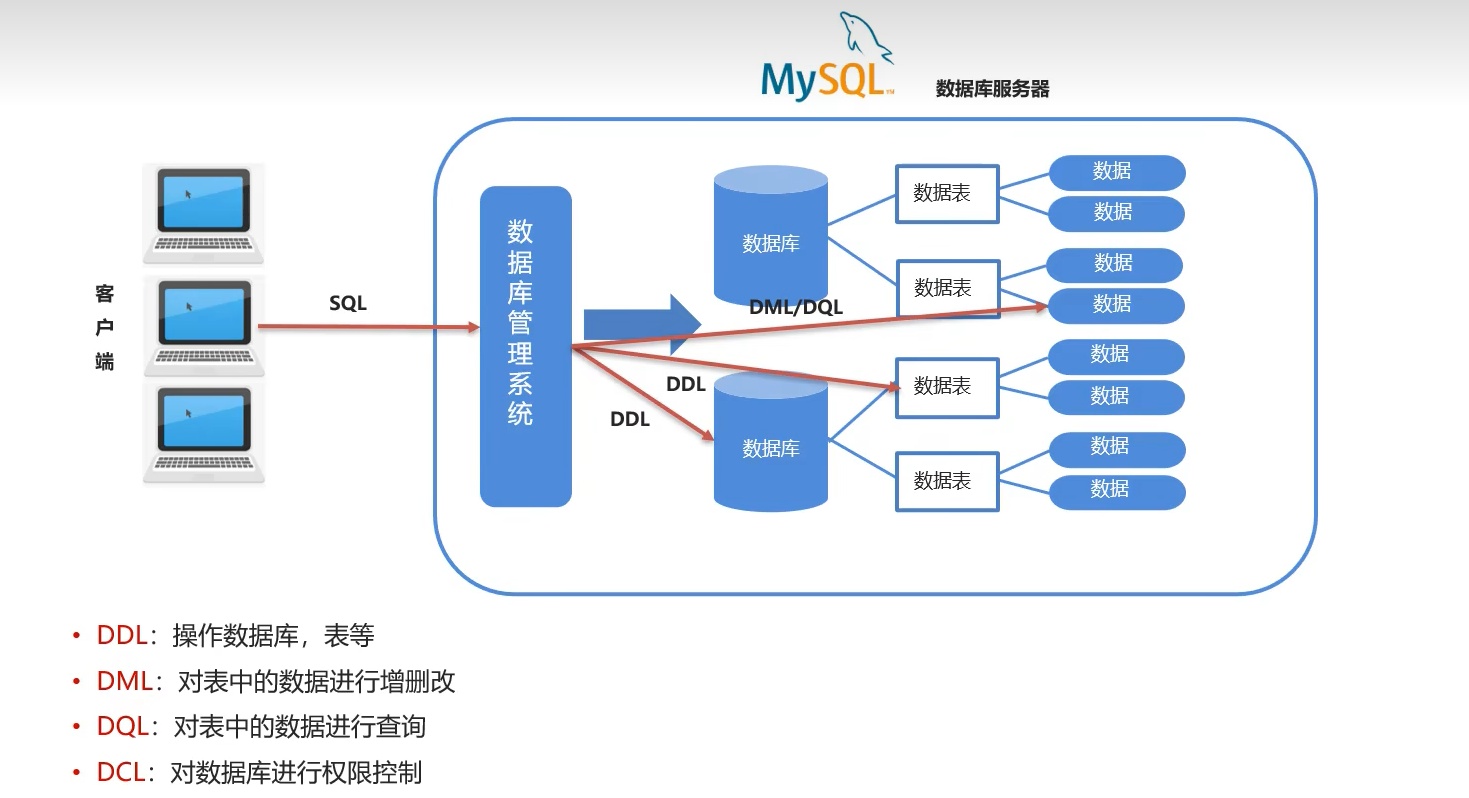
# 创建数据库 create database 数据库名; # 创建数据库,当指定的数据库不存在时才执行 create database if notexists 数据库名; # 在创建数据库的同时指定数据库的字符集(数据存储在数据库中采用的编码格式 utf8 gbk) create database 数据库名 character set utf8; create database if notexists 数据库名 character set utf8;
删除数据库
1 2 3 4
# 删除数据库 drop database 数据库名; # 删除数据库,当指定的数据库存在时才执行 drop database if exists 数据库名;
修改数据库
1 2
# 修改数据库的字符集 alter database 数据库名 character set utf8;
createprocedure proc_test2(IN a int,OUT r int) begin declare x intdefault0; -- 定义x int类型,默认值为0 declare y intdefault1; -- 定义y set x = a*a; set y = a/2; set r = x+y; end;
9.6.2 定义用户变量
用户变量:相当于全局变量,定义的用户变量可以通过 select @attrName from dual 进行查询
set @n=1; call proc_test2(6,@n); select @n from dual;
9.6.4 将查询结果赋值给变量
1
在存储过程中使用select..into..给变量赋值
示例
1 2 3 4 5 6 7 8 9 10
-- 查询学生数量 -- 注意在储存过程中使用SQL语句需要将结果赋值给变量,那么就需要使用into关键字来进 行赋值 createprocedure proc_test3(OUT c int) begin selectcount(stu_num) INTO c from students; -- 将查询到学生数量赋值给c end; -- 调用存储过程 call proc_test3(@n); select@nfrom dual;
-- 创建存储过程:添加学生信息 createprocedure proc_test4(IN snum char(8),IN sname varchar(20), IN gender char(2), IN age int, IN cid int, IN remark varchar(255)) begin insert into students(stu_num,stu_name,stu_gender,stu_age,cid,remark) values(snum,sname,gender,age,cid,remark); end; call proc_test4('20220108','小丽','女',20,1,'aaa');
-- 创建存储过程,根据学生学号,查询学生姓名 createprocedure proc_test5(IN snum char(8),OUT sname varchar(20)) begin select stu_name INTO sname from students where stu_num=snum; end; set@name=''; call proc_test5('20220107',@name); select@namefrom dual;
9.7.3 INOUT 输入输出参数
输入输出参数——该类型的参数既是输入参数也是输入参数。注意:此方式不建议使用,一般我们输入就用 IN 输出就用OUT,此参数代码可读性低,容易混淆。
示例
1 2 3 4 5 6 7
createprocedure proc_test6(INOUT str varchar(20)) begin select stu_name INTO str from students where stu_num=str; end; set@name='20220108'; call proc_test6(@name); select@namefrom dual;
9.8 存储过程中的流程控制
9.8.1 分支语句
if-then-else
1 2 3 4 5 6 7 8 9 10 11
-- 单分支:如果条件成立,则执行SQL if conditions then -- SQL end if; -- 如果参数a的值为1,则添加一条班级信息 createprocedure proc_test7(IN a int) begin if a=1then insert into classes(class_name,remark) values('Java2209','test'); end if; end;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- 双分支:如果条件成立则执行SQL1,否则执行SQL2 if conditions then -- SQL1 else -- SQL2 end if; -- 如果参数a的值为1,则添加一条班级信息;否则添加一条学生信息 createprocedure proc_test7(IN a int) begin if a=1then insert into classes(class_name,remark) values('Java2209','test'); else insert into students(stu_num,stu_name,stu_gender,stu_age,cid,remark) values('20220110','小花','女',19,1,'...'); end if; end;
case
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- case createprocedure proc_test8(IN a int) begin case a when1then -- SQL1 如果a的值为1 则执行SQL1 insert into classes(class_name,remark) values('Java2210','wahaha'); when2then -- SQL2 如果a的值为2 则执行SQL2 insert into students(stu_num,stu_name,stu_gender,stu_age,cid,remark) values('20220111','小刚','男',21,2,'...'); else -- SQL (如果变量的值和所有when的值都不匹配,则执行else中的这个SQL) update students set stu_age=18where stu_num='20220110'; endcase; end;
9.8.2 循环语句
while
1 2 3 4 5 6 7 8 9 10 11 12 13
-- while createprocedure proc_test9(IN num int) begin declare i int; set i =0; while i<num do -- SQL insert into classes(class_name,remark) values( CONCAT('Java',i) ,'....'); set i = i+1; end while; end; call proc_test9(4);
repeat
1 2 3 4 5 6 7 8 9 10 11 12 13
-- repeat createprocedure proc_test10(IN num int) begin declare i int; set i =1; repeat -- SQL insert into classes(class_name,remark) values( CONCAT('Python',i) ,'....'); set i = i+1; until i > num end repeat; end; call proc_test10(4);
loop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- loop createprocedure proc_test11(IN num int) begin declare i int ; set i =0; myloop:loop -- SQL insert into classes(class_name,remark) values( CONCAT('HTML',i) ,'....'); set i = i+1; # 结束循环的条件 if i=num then # 离开循环 leave myloop; end if; end loop; end; call proc_test11(5);
-- MySQL中, Concat_WS() 函数 用来通过指定符号,将2个或多个字段拼接在一起,返回拼接后的字符串。 createprocedure proc_test12(outresultvarchar(200)) begin # 游标变量 declare cid int; # 游标变量 declare cname varchar(20); # 计数变量 declare num int; # 计数变量 declare i int; # 每条数据 declare str varchar(100); # 查询语句执行之后返回的是一个结果集(多条记录),使用游标遍历查询结果集 declare mycursor cursorforselect class_id,class_name from classes; # 记录总数据量 selectcount(*) into num from classes; # 打开游标 open mycursor; set i =0; # 开始遍历游标 while i<num do # 提取游标中的数据,并将结果赋值给游标变量 fetch mycursor into cid,cname; set i = i+1; # set str=concat_ws('~',cid,cname); 不同的写法 select concat_ws('~',cid,cname) into str; setresult= concat_ws(',',result,str); end while; close mycursor; end; # 案例测试 set@r=''; call proc_test12(@r); select@rfrom dual;
-- 示例 createtrigger tri_test1 after inserton students foreachrow insert into stulogs(time,log_text) values(now(), concat('添加',NEW.stu_num,'学生信息'));
10.3 查看触发器
1
show triggers;
10.4 删除触发器
1
droptrigger 触发器名称;
10.5 NEW与OLD
1 2 3
触发器用于监听对数据表中数据的insert、delete、update操作,在触发器中通常处理一些DML的关联操作;我们可以使用 NEW 和 OLD 关键字在触发器中获取触发这个触发器的DML操作的数据 NEW: 在触发器中用于获取insert操作添加的数据、update操作修改后的记录 OLD: 在触发器中用于获取delete操作删除前的数据、update操作修改前的数据
NEW
insert操作中:NEW表示添加的新记录
1 2 3 4
createtrigger tri_test1 after inserton students foreachrow insert into stulogs(time,log_text) values(now(), concat('添加',NEW.stu_num,'学生信息'));
update操作中:NEW 表示修改后的数据
1 2 3 4
-- 创建触发器 : 在监听update操作的触发器中,可以使用NEW获取修改后的数据 createtrigger tri_test2 after updateon students foreachrow insert into stulogs(time,log_text) values(now(), concat('修改学生信息为:',NEW.stu_num,NEW.stu_name));
OLD
delete操作中:OLD表示删除的记录
1 2 3
createtrigger tri_test3 after deleteon students foreachrow insert into stulogs(time,log_text) values(now(), concat('删除',OLD.stu_num,'学生信息'));
update操作中:OLD表示修改前的记录
1 2 3
createtrigger tri_test2 after updateon students foreachrow insert into stulogs(time,log_text) values(now(), concat('将学生姓名从【',OLD.stu_name,'】修改为【',NEW.stu_name,'】'));